
Redis 高级特性 Pipeline (管道) 使用和基本测试
都说 Pipeline 有很大好处,但是能量是守恒的,好坏也是相对的。
所以我们主要来测试看看 Pipeline 的利弊。
带着几个问题我们来进行基本的测试。
1. Pipeline 对命令数量是否有限制?
2. Pipeline 打包执行多少命令合适?
3. Pipeline 批量执行的时候,是否对Redis进行了锁定,导致其他应用无法再进行读写?
Redis 常规使用方式
我们都知道Redis 是单线程的,那么在常规使用情况下,我们使用 Redis ,如下代码执行是什么流程呢?
$key1 = "abc1";
$key2 = "abc2";
$key3 = "abc3";
$redisObj->set($key1, 1);
$redisObj->set($key2, 2);
$redisObj->set($key3, 3);
Redis 的执行方式是逐条命令: 发送命令->执行->返回执行结果。
如图:

什么是 pipeline 呢?
知道了常规的使用方式,那么我们再来看看 pipeline 模式,pipeline 模式则是将执行的命令写入到缓冲中,最后由exec命令一次性发送给redis执行返回。
我们以灌一个list来进行测试,以20000条list数据为例,来对比一下常规模式的的写入和 pipeline 模式的写入。
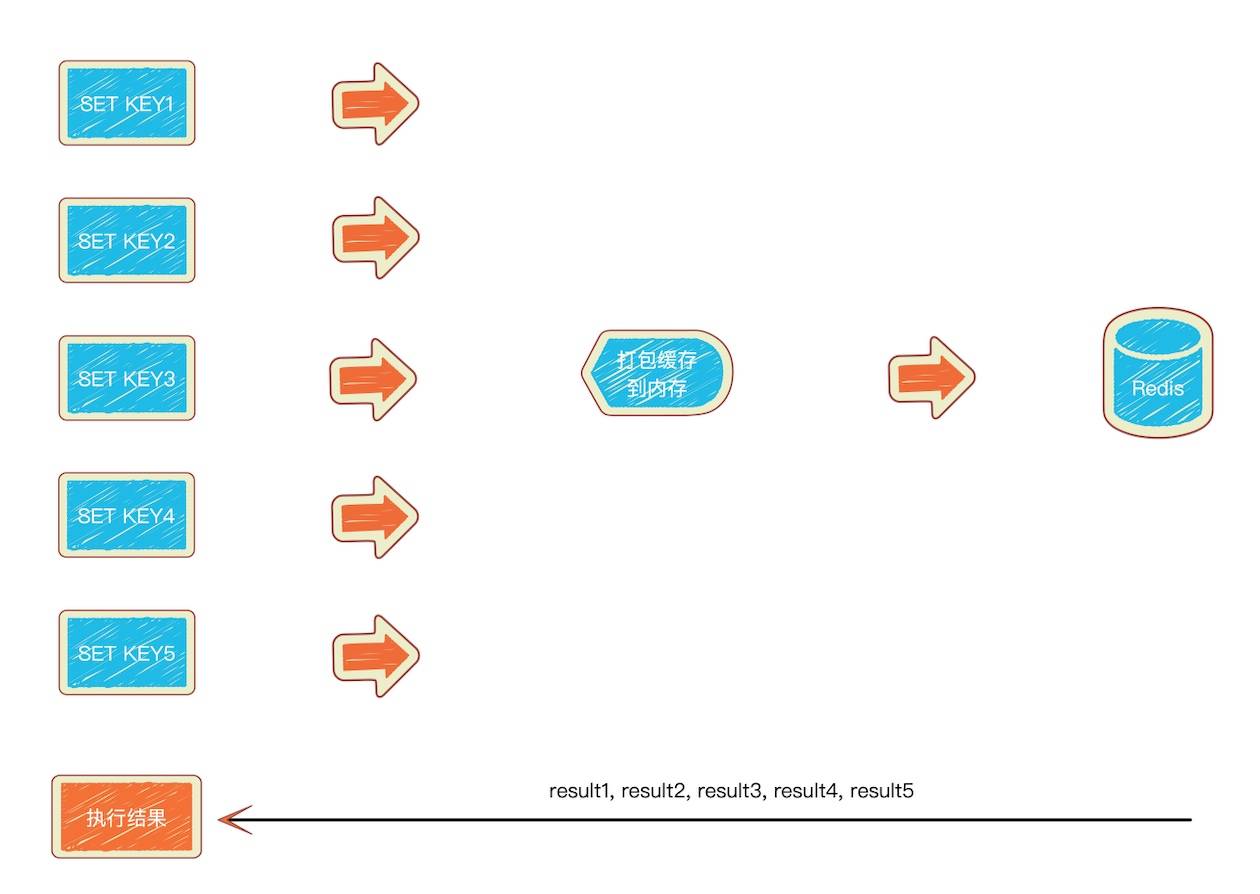
Redis pipeline 的执行方式:
打包开始->缓存->打包结束->发送->执行->返回执行结果。
如图:

逐条写模式(常规模式)
<?php
$redisObj = new \Redis();
$redisObj->connect('127.0.0.1', 6379);
$time_start = microtime(true);
$mcKey = "lpush:normal";
for ($i = 0; $i < 20000; $i++)
{
$redisObj->lPush($mcKey, $i);
}
$time_end = microtime(true);
$time = $time_end - $time_start;
echo "逐条写模式耗时: {$time}\n";
Pipeline(管道) 模式
<?php
$redisObj = new \Redis();
$redisObj->connect('127.0.0.1', 6379);
$time_start = microtime(true);
$redisObj->multi(Redis::PIPELINE);
unset($time, $time_end, $mcKey);
$mcKey = "lpush:pipeline";
for ($i = 0; $i < 20000; $i++)
{
$redisObj->lPush($mcKey, $i);
}
$redisObj->exec();
$time_end = microtime(true);
$time = $time_end - $time_start;
echo "pipeline 模式运行耗时:{$time}\n";
我们看看,两者的执行结果:
#php t.php
逐条写模式耗时: 1.0443658828735
pipeline 模式运行耗时:0.045078039169312
根据结果可以看出,pipeline 模式的耗时比 逐条写模式 提升了20倍。
Pipeline(管道) 的优点:
pipeline通过打包命令,一次性执行,可以节省连接->发送命令->返回结果所产生的往返时间,- 减少的I/O的调用次数。
Pipeline(管道) 的缺点:
pipeline每批打包的命令不能过多,因为pipeline方式打包命令再发送,那么redis必须在处理完所有命令前先缓存起所有命令的处理结果。这样就有一个内存的消耗。pipeline是责任链模式,这个模式的缺点是,每次它对于一个输入都必须从链头开始遍历(参考Http Server处理请求就能明白),这确实存在一定的性能损耗。pipeline不保证原子性,如果要求原子性的,不推荐使用pipeline
问题解答
Q、Pipeline 对命令数量是否有限制?
A、没有限制,但是打包的命令不能过多,对内存的消耗就越大。
Q、Pipeline 打包执行多少命令合适?
A、查询 Redis 官方文档,根据官方的解释,推荐是以 10k 每批 (*注意:这个是一个参考值,请根据自身实际业务情况调整)。
IMPORTANT NOTE: While the client sends commands using pipelining, the server will be forced to queue the replies, using memory. So if you need to send a lot of commands with pipelining, it is better to send them as batches having a reasonable number, for instance 10k commands, read the replies, and then send another 10k commands again, and so forth. The speed will be nearly the same, but the additional memory used will be at max the amount needed to queue the replies for this 10k commands. https://redis.io/topics/pipelining
Q、Pipeline 批量执行的时候,是否对Redis进行了锁定,导致其他应用无法再进行读写?
A、Redis 采用多路I/O复用模型,非阻塞IO,所以Pipeline批量写入的时候,一定范围内不影响其他的读操作。
以上为个人总结,如有不对,欢迎指正。